GraphQL CLI is back! Your Swiss Army Knife for the GraphQL ecosystem


GraphQL CLI is back! Your Swiss Army Knife for the GraphQL ecosystem
Production-ready GraphQL app in seconds
TL;DR;
GraphQL CLI is a popular command-line tool providing various tools for creating and maintaining GraphQL based applications
Prisma recently transferred the project to The Guild — and we completely rewrote it and closed over 100 issues
We’ve already fixed and added many commands but we are looking to learn and integrate with tools and companies across the ecosystem!
You can now generate a full stack working app, from a GraphQL schema model, in 2 minutes using the init+generate commands!
This is an alpha phase — we want your feedback, as a user and as a tool creator — Please create an issue and join our Discord channel
Overview
The GraphQL CLI provides:
- Helpful commands to improve your daily workflows, from starting a project to maintaining it for the long run
Rich ecosystem and compatibility with libraries, editors and IDEs based on a unified graphql-config
A powerful plugin system to extend GraphQL CLI with custom commands — supported by the community and The Guild
The main target of the GraphQL CLI is to provide a default entry point for the community to use proven techniques for building and deploying GraphQL enabled applications while being vendor agnostic.
Advanced developers and tool creators can extend graphql-cli to provide additional capabilities while still benefiting from a robust set of default commands for daily use — We want to use the CLI to encourage open collaborations between different tool creators.
History
Over the years the GraphQL ecosystem flourished and evolved towards more production-ready use cases with a large number of active community packages available.
GraphQL evolved thanks to the large community and the many supporting libraries it has created.
The GraphQL CLI has become a place for the community to share ideas and best practices across different solutions and libraries thanks to the push from Prisma.
The Guild took over GraphQL CLI to continue on that promise:
- Making it as easy as possible create and deploy GraphQL based applications
- Making it easier to maintain production-grade, scalable GraphQL applications
All of that while:
- Keeping the CLI updated with the latest solutions and practices
- Making it extensible and configurable without any solution bias — any approach and architecture could easily integrate and benefit from the CLI
- Keeping the industry leading, long term open source library maintenance standard that The Guild is known for
Try it out today
We’ve already refactored most of the code, created a new structure, closed and fixed all the known issues and released a new alpha version.
Install new version (follow the latest alpha in the releases page):
$ npm install graphql-cli@canaryCreate a new project with GraphQL CLI by running:
$ graphql initGraphQL CLI will guide you and after only few seconds, your project will be ready to use!
End-to-end type safety
Code generation + end-to-end type safety is a hot topic nowadays. Thanks to tools like GraphQL Code Generator we’re able to produce flexible code for both backend and frontend, just from GraphQL Schema and Operations with Fragments.
In GraphQL CLI, you get it out of the box by running:
$ graphql codegenDiscover what can be generator on GraphQL Codegen website.
Production ready GraphQL Backend
Thanks to integration with GraphBack, you’re able to produce an entire Data Base, GraphQL schema with operations and strongly typed resolvers.
$ graphql generateTake a look at GraphBack website to learn more.
Bulletproof your GraphQL API
GraphQL CLI comes with most of the features of GraphQL Inspector.
With just few simple commands you’re able to:
- detect breaking or dangerous changes
- validate Operations and Fragments at build time
- analyze the usage of GraphQL Schema (unused types and fields)
- find duplicates and similar GraphQL Types
- serve faked GraphQL schema
$ graphql diff
$ graphql similar
$ graphql validate
$ graphql coverage
$ graphql serveVisit GraphQL Inspector docs.
This is just the start!
The GraphQL CLI has been rewritten in order to make it extremely customizable and extensible.
Our goal is to make sure that any tool can work and benefit from this setup.
The CLI offers freedom for anyone to create any command that will extend their workflows by creating separate library. Alternatively you can open a conversation about new command that can be included into our supported set of commands.
If you prefer to use all of the Apollo toolings and products, AppSync’s solutions, Prisma, OneGraph, Hasura, Postgraphile or any other tool — we want to make the GraphQL CLI the best supporting tool for your stack.
We won’t impose any choices on the users. We want the community to lead and have template generators for any technology.
This project is completely open and free from any bias and we are open to any feedback and collaboration with anyone from the community. Please reach out!
Example use cases of GraphQL CLI
The CLI gives you the ability to build a base template with your favorite stack and tools.
Templates can be based on graphql.js, Apollo, Nexus, TypeGraphQL or anything other framework. Creating a custom template may help to enforce a specific structure that fits your product and company.
The CLI comes with two default templates that provide a seamless starting point for both backend and frontend, both could be pushed to production in a short time period.
Additionally, for existing applications, the CLI will support migrating existing databases or REST API to GraphQL.
Production-ready GraphQL app in seconds
Or “Making GraphQL easy — From nothing to a full production-ready app in 2 minutes — with any stack!”
There are many great GraphQL boilerplate repositories on available Github.
But when using those, it is often hard to adjust those to real business cases.
As an alternative to sample apps, developers can rely on frameworks that provide a high level of abstraction.
But technologies that offer rapid application development might often come at the cost of the maintenance and flexibility that can seriously limit the extensibility of your application server.
$ graphql initWe believe that making it easy to start with GraphQL is extremely important, but without sacrificing other factors like extensibility, scalability and wider control.
Simple shouldn’t equal bad architecture.
GraphQL CLI addresses this very important problem in the core by utilizing two main concepts: code generation and rich ecosystem of base templates.
The graphql init command is trying to address three simple questions:
Can we build an application template that can offer production-ready capabilities and yet is simple enough to work without extensive learning?
Can we provide our data model as input to the GraphQL engine and benefit from autogenerated data access methods?
Can we use the same techniques for an existing application and generate partial models?
You can think of it as a smarter
create-react-app, that works on a full-stack and understands your data model.
We are calling leading boilerplate creators and frameworks to collaborate with us. We can help you expose your boilerplates also as templates for the init command.
We would also love feedback from internal infrastructure teams from companies who wish to create their own best practices and guidelines.
For more information please refer to https://github.com/aerogear/graphback
One config to rule them all — GraphQL Config
At the heart of a project created using GraphQL CLI is the GraphQL Config file. It lets the CLI know where all of the GraphQL parts are.
Config is essential for CLI templates and for the command creators that can utilize its extensibility to save additional metadata. Thanks to graphql-config, the CLI can provide seamless support for every extension and streamline development experience on top of the GraphQL CLI generated projects and corresponding templates.
For more information about GraphQL Config, you can click here to learn more.
Migration from 3.x.x to 4.x.x
We have provided a complete migration document for existing users who wish to update to the latest version of the CLI. Please keep in mind that CLI is still in the alpha phase and we are looking for the feedback before officially releasing a final version of the CLI.
Please follow https://github.com/Urigo/graphql-cli/blob/master/MIGRATION.md migration guide.
Help us to shape the GraphQL ecosystem
Start using the GraphQL CLI today!
Even though we are in an alpha phase, the CLI is fully usable and ready for the community to adopt it.
Our team is open to any suggestions and ideas for new commands.
We will support and answer all your questions on Github and on our Discord channel.
The Guild is taking over maintenance of merge-graphql-schemas, so let’s talk about GraphQL Schema management
How stitching, federation and modules all fit together?

TL;DR
After many years of supporting the community, the OK-Grow! Team is transferring ownership and maintenance of merge-graphql-schemas to The Guild
merge-graphql-schemas will be added to the existing Schema management tools already created by The Guild (GraphQL-Toolkit, GraphQL Modules, GraphQL Inspector and graphql-code-generator)
This is a continuation of making order in the schema management tools across the ecosystem
- If you are at GraphQL-Conf this week, come say hi
merge-graphql-schemas is a popular library in the GraphQL Ecosystem.
It’s one of the first tools people encounter once they went through their first GraphQL implementation and start to wonder how to organize their GraphQL server code.
The OK-Grow! Team has been maintaining that library for years, filling a needed gap in the ecosystem.
At the same time, The Guild has been working on similar tools around GraphQL schema and module management.
Today we are happy to announce that we are joining forces and merging our efforts to create open source, easy and scalable solutions for GraphQL servers.
In a couple of days of work we’ve refactored the underlying implementation of merge-graphql-schemas to use GraphQL-Toolkit under the hood, we can close around 90% of the open issues on the library while making sure all existing tests are passing!
We are happy to announce a new beta release (1.6.0-beta) is out!
If you are a user of merge-graphql-schemas please give the new version a try before we make a full release.
yarn add merge-graphql-schemas@nextWhat’s next?
The Guild has been busy for a while creating scalable GraphQL solutions around schema and modules management for large teams.
The main issue we see today in the ecosystem is that there is no clear overview of which tools solve which problem area.
In order to make sure we solve the right issues in the right place, we need clear boundaries between the different libraries and solutions.
Let’s try to break down the different areas of solutions needed when splitting GraphQL schemas:
Building and executing GraphQL according to spec — The Engine
Structuring multiple building blocks of the same server into a single executable schema — GraphQL Tools and Frameworks
Structuring multiple servers instances into a single executable schema — Federation
Now we can gather all use cases from the community, put them as tests on the right library and make sure we solve each one of them.
The Engine
The Engine (in the Javascript world the most popular one is graphql.js) should be responsible of taking a ready schema and resolvers, validate the objects, introspecting them and executing documents against them at runtime.
That GraphQLSchema input must be strictly valid according to the GraphQL Spec.
That’s why manipulating a ready GraphQLSchema object can be hard. GraphQLSchema object should be the final object to input the engine.
The Engine should not care or help you create that final schema or resolvers.
GraphQL Management Tooling
We can think of the Engine like a Web Browser — It is responsible of taking a spec (Javascript and HTML) and execute it in a consistent way.
But the browser doesn’t care about how you create that Javascript and HTML bundle.
That means that like we use babel, Typescript or frameworks for manipulating code to generate spec-compliant output, we can do the same for GraphQL with graphql.js as our target “browser”.
Those tools should help you organize and manage your code in your preferred way, without needing to be bound by what graphql.js expects.
One of the main things that those tools can provide us is an easy way to split the code and the schema into small chunks and later merge them with different merging strategies.
Just like Javascript frameworks, using those tools can get you very far and make it easy to handle huge codebases with many different teams.
Federation
In some scenarios you would want to run completely different servers and merge them somehow into a single GraphQL gateway.
Schema stitching and schema federation are attempts to make that work less manual.
There are some use cases where you might want those types of solutions, but they also add a lot of complexity so it’s important to understand very well why you really can’t handle your use case in a build-tool type of solution, and to know if Federation is an end goal or a stepping point to get you further.
Breaking it all down
After years of working with GraphQL, from small applications to managing schemas across huge corporations, creating open source tools and best practices around those, we want to share it all with the community.
In the next few weeks we will publish articles about each solution type, the tools around and when you should use what.
Things like why you should split your schemas, why not, what are the existing solutions out there and when to use each one.
We will also add examples of all those use cases into our main tutorial.
We need you to send us your questions, use cases and ideas — we want to make sure we cover as many use cases as possible across our libraries and other libraries we contribute too as well (some things might fit into graphql.js or Apollo for example).
You can comment here or submit issues into any of our repositories.
Thank you OK-Grow!
I want to personally thank the OK-Grow! Team and specifically Paul for being a very early adopter and supporter of the GraphQL community.
The work you have done so far has been amazing and valuable and we are dedicated to continue to support our community in the best way possible.
Sofa — The best way to REST (is GraphQL)
Ending the REST vs GraphQL debate once and for all

TL;DR
Don’t choose between REST and GraphQL — create a fully RESTful API automatically from your GraphQL implementation (with a library and a single line of code)
Get most of the benefits of GraphQL on the backend and frontend, while using and exposing REST
Support all your existing clients with REST while improving your backend stack with GraphQL
Create custom, perfectly client-aligned REST endpoints for your frontend simply by naming a route and attaching a query
- Stop arguing about REST vs GraphQL. Use GraphQL, generate REST and get the best from both
- In the other way around (REST to GraphQL) you won’t get the best of both world but less powerful, harder to maintain server implementation with some of the benefits of GraphQL. It is a good and fast start for a migration though..
Wait, WHAT!?
Many articles have been written about the pros and cons of GraphQL and REST APIs and how to decide which one to use. I’m not going to repeat those here..
A lot of time and energy spent by smart consultants to write those articles, read those articles, while most of them are finished with the “it depends on your use case” summary, without actually specifying those use cases!
I’ve been working with REST, GraphQL and SOAP APIs for many years. So I thought, why not come up with a list of those use cases and for each one of those to check — what can’t you do in GraphQL that you can do with REST and what you wouldn’t want to do with GraphQL and you would prefer REST.
After creating that list, I suddenly had a thought — what if there was another option — what if my powerful GraphQL server could just generate a REST API for me?
Then I could get the best of both worlds!
The more I dived into the idea and implementation then more I realized it’s not only that we can have both types of APIs created for us, but even if we just want to expose REST APIs, and none of our clients use GraphQL, GraphQL is the best way the create REST APIs!
How does the above sentence even make sense?!
Usually when we (The Guild) help companies and organizations to modernize their APIs, the first to understand the benefits of GraphQL are the frontend developers, for obvious reasons. But as soon as the backend developers “Get it”, they become the biggest advocates of the technology. But they still need to support existing clients and 3rd party partners.
That’s why those newly generated REST APIs get a lot of the features and benefits from the internal GraphQL implementation that make backend developers happy:
Fully generated documentation that is always up-to-date (Swagger, OpenAPI and GraphiQL)
Truly RESTful API out of the box
GraphQL Subscriptions as Webhooks
Runtime validation of data — be 100% sure that fetched data matches schema’s and query’s structure. You send exactly what I want to send, string is a string, an object has exactly the same properties.
Creating a custom endpoint is now a matter of choose a route name and attaching a query to it. done. No more manual work of creating and maintaining client specific endpoints!
Use GraphQL’s philosophy of evolving APIs through schemas — no more painful V1 — V2 API migrations.
Use modern technology that is easier to hire people to. Companies like Facebook, Airbnb and others have moved to GraphQL. None of them has gone back.
The power of GraphQL resolvers to create your API implementation, instead of manually written controllers from MVC
What I get from having resolvers?
- Easier to transform data so it matches the response (GraphQL Schema). That’s because every entity has its own resolvers, so the mapping is moved into smaller pieces and reused across an entire app.
- GraphQL allows you to easily share data across every resolver, we call it Context.
- Forces you to define and resolve data in an opinionated way that actually helps building an API. It runs functions in parallel (functions that are nested at the same level), handles async and at the end, it is responsible of merging all of that into a single object, so you don’t have to think about it.
Sofa — Use GraphQL to create RESTful APIs
So we created Sofa (pun intended), an open source library you install on your GraphQL server to create a fully RESTful and configurable API gateway. Use GraphQL to REST.
“How to” tutorial
Let’s create a short step by step tutorial on how to create a RESTful API.
Step 1: npm install the `sofa-api` package and add the following line of code:
import sofa from 'sofa-api';
import express from 'express';
const app = express();
app.use(
sofa({ schema })
);Step 2: Go REST on a Sofa, you’re done.
Kamil Kisiela added Sofa to the SpaceX GraphQL API implementation by Carlos Rufo, in a single commit.
Check out the fully generated REST endpoints, the Swagger live documentation, GraphiQL editor and the GraphiQL-Explorer!
By the way, what you see here is a REST API, generated on top of a GraphQL API, created on top of another REST API….
Why did you do that for!?!?
Gradually migrating from old REST implementations
This is actually a good direction to go. In many of the companies we work with, they’ve created REST API layers using old technology on top of their original web-services.
But those REST implementations are problematic (for all the obvious reasons people choose to move to GraphQL).
So our way to go is to create GraphQL implementations on top of those REST layers, migrate the clients to those implementations and then gradually remove the old RESTful layer and call the services directly.
Using Sofa made those transitions much faster because we can offer all the existing clients to migrate to our GraphQL implementation without actually using GraphQL themselves. We simply expose the same REST endpoints on top of GraphQL and they are moving to our layer happily because we can accommodate all of their requests and custom REST endpoints much faster than the original, old REST implementations.
Give me more details
Sofa uses Express by default but you can use any other server framework. Sofa is also GraphQL server implementation agnostic.
Head over to the Sofa website for documentation and to the Github repository for reporting issues and helping out.
How Sofa works?
Under the hood, Sofa turns each field of Query and Mutation types into routes. First group of routes is available only through GET method, mutations on the other hand get POST.
Sofa uses GraphQL’s AST to create an operation with all possible variables (even those deeply nested) and knows exactly what to fetch. Later on it converts the request’s body into operation’s variables and execute it against the Schema. It happens locally, but it’s also possible to use an external GraphQL Server or even Apollo Link.
Right now Sofa has a built-in support for Express but it’s totally possible to use a different framework. The main concept stays exactly the same so only the way we handle the request differs across different server implementations.
GraphQL Subscriptions as Webhooks?
The way it works is simply, you start a subscription by calling a special route and you get a unique ID that later on might be used to update or even stop the subscription. Subscriptions are Webhooks. Sofa knows exactly when there’s an even happening on your API and notifies you through the endpoint you’ve assigned a subscription to.
Models / Resources?
In some cases you don’t want to expose an entire object but just its id. How you’re able to do that with Sofa? You need to have two queries. First one has to return a single entity based just on its id (which would be an argument) and the second one should resolve a list of those. Also the names should match, for example a resource called User should have two queries: user(id: ID): User and users: [User]. Pretty much the same thing you would do with REST.
type Query {
user(id: ID!): User
users: [User]
}Before Sofa creates the routes, it looks for those Models and registers them so when the operations are built you don’t fetch everything but only an id.
But what if you want to fetch an entire object but only in few places?
There’s an option called ignore that allows you to do that. You simply pass a path in which you want to overwrite the default behavior.
Given the schema below, you would get just author’s id.
type Book {
id: ID
title: String!
author: User!
}extend type Query {
book(id: ID!): Book
books: [Book]
}With ignore: ['Book.author']you end up with an entire User object.
sofa({
...,
ignore: ['Book.author'],
})Swagger and OpenAPI
Thanks to GraphQL’s type system Sofa is able to generate always up-to-date documentation for your REST API. Right now we support Swagger and its OpenAPI specification but it’s really easy to adopt different specs.
import sofa, { OpenAPI } from 'sofa-api';
const openApi = OpenAPI({
schema,
info: {
title: 'Example API',
version: '3.0.0',
},
});
app.use(
sofa({
schema,
onRoute(info) {
openApi.addRoute(info, {
basePath: '',
});
},
})
);
openApi.save('./swagger.json');Summary
sofa-api makes it extremely easy to create a RESTful API with all the best practices of REST from a GraphQL server using all its power.
Stop wasting your life arguing about REST vs GraphQL — Be productive, get the benefits of both worlds and move into the future of API development.
I hope this would become the last REST vs. GraphQL article out there…. if you think it won’t, comment with a use case and let’s try it out!
Thanks to Kamil Kisiela for working with me on this and making this library a reality!
Follow us on GitHub and Medium, we are planning to release many more posts in the next couple of weeks about what we’ve learned using GraphQL in recent years.
GraphQL Modules — Feature based GraphQL Modules at scale

GraphQL Modules — Feature based GraphQL Modules at scale
Today we are happy to announce that we are open sourcing a framework we’ve been using for the past couple of months in production — GraphQL Modules!
Yet another framework? well, kind of.. GraphQL Modules is a set of extra libraries, structures and guidelines around the amazing Apollo Server 2.0.
You can and should use them as completely separate packages, each one is good for different use cases, but all together they represent our current philosophy of building large scale GraphQL servers.
We would love to get feedback from the Apollo team and if they wish to use those ideas and integrate them into Apollo Server we would love to contribute. That’s why we’ve developed it as a set of independent tools under a single monorepo.
The basic concept behind GraphQL Modules is to separate your GraphQL server into smaller, reusable, feature based parts.
A basic and initial implementation of a GraphQL server usually includes:
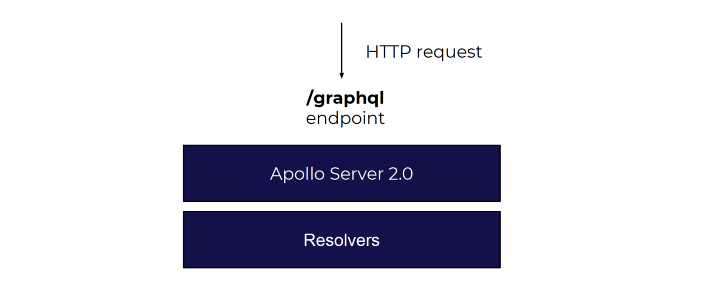
A more advanced implementation will usually use a context to inject things like data models, data sources, fetchers, etc, like Apollo Server 2.0 provides us with:
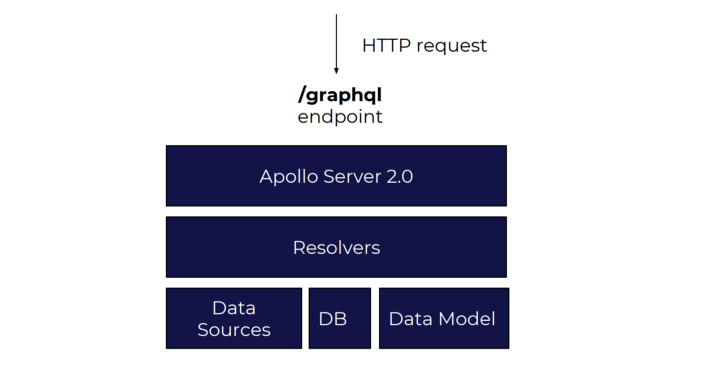
Usually, for simple use cases, the example above will do.
But as applications grow, their code and schematic relationships becomes bigger and more complex, which can make schema maintenance a hard and agonizing thing to work with.
Some of the more old school, MVC frameworks adds few more layers after the resolvers layer, but most of them just implement separation based technical layers: controllers, models, etc.
We argue that there is a better approach of writing your GraphQL Schema and implementation.
We believe you should separates your GraphQL schema by modules, or features, and includes anything related to a specific part of the app under a “module” — which is just a simple directory. Each one of the GraphQL Modules libraries would help you in the gradual process of doing that.
The modules are being defined by their GraphQL schema — so we’ve taken the “GraphQL First” approach lead by Apollo and combined it together with classic modularization tooling to create new ways of writing GraphQL servers!

The GraphQL Modules toolset has tools to help with:
Schema Separation — declare your GraphQL schema in smaller pieces, which you can later move and reuse.
Tools designed to create independent modules — each module is completely independent and testable, and can be shared with other applications or even open sourced if needed
Resolvers Composition — with GraphQL Modules you can write your resolver as you wish, and let the app that hosts the module to wrap the resolvers and extend them. It’s implemented with a basic middleware API, but with more flexibility. That means that you can, for example, implement your entire module without knowing about the app authentication process, and assume that
currentUserwill be injected for you by the app.A clear, gradual path from a very simple and fast, single-file modules, to scalable multi-file, multi-teams, multi-repo, multi-server modules.
A scalable structure for your GraphQL servers — managing multiple teams and features, multiple microservices and servers
and more advanced tools, which you can choose to include when your schema gets into massive scale:
Communication Bridge — We also let you send custom messages with payload between modules — that means you can even run modules in different microservices and easily interact between them.
Dependency Injection — Implement your resolvers, and later, only when you see fit, improve their implementation by gradually introducing dependency injection. It also includes richer toolset around testing and mocking.
A Basic Example
In the following example, you can see a basic implementation for GraphQL Modules server, with 2 modules: User and Chat. Each module declares only the part that is relevant to it, and extends previously declared GraphQL types.
So when User module is loaded, the type User is created, and when Chat module is loaded, the type User being extended with more fields.
import { GraphQLModule } from '@graphql-modules/core';
import { UserModule } from './user-module';
import { ChatModule } from './chat-module';
export const appModule = new GraphQLModule({
imports: [
UserModule,
ChatModule,
],
});import { GraphQLModule } from '@graphql-modules/core';
import gql from 'graphql-tag';
export const ChatModule = new GraphQLModule({
typeDefs: gql`
# Query declared again, adding only the part of the schema that relevant
type Query {
myChats: [Chat]
}
# User declared again- extends any other `User` type that loaded into the appModule
type User {
chats: [Chat]
}
type Chat {
id: ID!
users: [User]
messages: [ChatMessage]
}
type ChatMessage {
id: ID!
content: String!
user: User!
}
`,
resolvers: {
Query: {
myChats: (root, args, { getChats, currentUser }) => getChats(currentUser),
},
User: {
// This module implements only the part of `User` it adds
chats: (user, args, { getChats }) => getChats(user),
},
},
});import { appModule } from './modules/app';
import { ApolloServer } from 'apollo-server';
const { schema, context } = appModule;
const server = new ApolloServer({
schema,
context,
introspection: true,
});
server.listen();import { GraphQLModule } from '@graphql-modules/core';
import gql from 'graphql-tag';
export const UserModule = new GraphQLModule({
typeDefs: gql`
type Query {
me: User
}
# This is a basic User, with just the basics of a user object
type User {
id: ID!
username: String!
email: String!
}
`,
resolvers: {
Query: {
me: (root, args, { currentUser ) => currentUser,
},
User: {
id: user => user._id,
username: user => user.username,
email: user => user.email.address,
},
},
});You can and should adopt GraphQL Modules part by part, and you can try it now with your existing GraphQL server.
What does a “module” contain?
Schema (types declaration) — each module can define its own Schema, and can extend other schema types (without explicitly providing them).
Thin resolvers implementation — each module can implement its own resolvers, resulting in thin resolvers instead of giant files.
Providers — each module can have its own Providers, which are just classes/values/functions that you can use from your resolvers. Modules can load and use providers from other modules.
Configuration — each module can declare a strongly-typed config object, which the consuming app can provide it with.
Dependencies — modules can be dependent on other modules (by its name or its
GraphQLModuleinstance, so you can easily create an ambiguous dependency that later could be changed).
GraphQL Modules libraries
GraphQL Modules is built as a toolkit, with the following tools, which you should individually and gradually adopt:
@graphql-modules/epoxy
- That will probably be the first tool you want to introduce into your server. The first step into organizing your server in a feature based structure
- Epoxy is a small util that manages the schema merging. it allow you to merge everything in your schema, starting from types to enums, unions, directives and so on.
- This is an important feature of GraphQL Modules — you can use it to separate your GraphQL types to smaller pieces and later on combine them into a single type.
- We took the inspiration from merge-graphql-schemas, and added some features on top of it to allow custom merging rules to make it easier to separate your schema.
@graphql-modules/core
Resolvers Composition — manages the app’s resolvers wrapping
Context building — each module can inject custom properties to the schema, and other modules can use it (for example, auth module can inject the current user, and other modules can use it)
Dependency injection and module dependencies management — when you start, there is no need of using DI is your server. but when your server gets big enough with a large number of modules which depends on each other, only then, DI becomes a very help thing that actually simplifies your code a lot. USE ONLY WHEN NECESSARY ;)
You can find more tooling at your disposal like:
@graphql-modules/sonar — a small util that helps you to find GraphQL schema and resolvers files, and include them.
@graphql-modules/logger — a small logger, based on winston 3, which you can easily use in your app.
Get Started
First thing, don’t go full in! Start by simply moving your code into feature based folders and structures with your existing tools.
Then head over to https://graphql-modules.com/ and check out our tools and use them only when you see that they solve a real problem for you! (for us it has)
Also check out the repo’s README and a number of example apps.
You probably have many questions — How does this compare to other tools, how to use those libraries with X and so on.
We will publish a series of blog posts in the coming weeks that will dive deep into each of the design decisions made here, so we want to hear your thoughts and questions, please comment here or on the Github repository!
Going to GraphQL Summit? I will be there and would love to get your questions and feedback on behalf of our team.
All those tools were built by a passionate group of individual open source developers, otherwise known as The Guild.
Below there is a section of more deep dive thoughts that we will publish separate posts about in the coming weeks:
Core Concepts and deep dive
Modularizing a schema
Everyone is talking about schema stitching and GraphQL Bindings. Where does that fit into the picture?
Schema stitching is an amazing ability and concept, which helps you merge separated GraphQL servers into a single endpoint and opens up a lot of exciting use cases.
But, with all the excitement, we’ve missed something much more basic than that — sometimes we still want to work on a single logical server, but we just want to separate the code according to features.
We want to be able to do most of the merging work at build time, and only if really necessary, do the rest of the merging at runtime as a last resort.
We want to split the code into separate teams and even create reusable modules which define their external APIs by a GraphQL Schema.
Those modules can be npm modules, microservices or just separate folders inside a single server.
Separating your schema to smaller parts is easier when you are dealing with typeDefs and resolvers— it’s more readable and easy to understand.
We also wanted to allow developers to extend only specific types, without creating the entire schema. With GraphQL schema, you have to specify at least one field under Query type, which is something that we did not want to enforce on our users.
We see our approach as complementary to Schema Stitching and works together with it.
Feature-based implementation
One of the most important things in GraphQL Module’s approach is the feature-based implementation.
Nowadays, most frameworks are separating the layers based on the role of the layer — such as controllers, data-access and so on.
GraphQL Modules has a different approach — separate to modules based on your server’s features, and allow it to manage its own layers within each module implementation.
It’s easier to think about apps in a modular way, for example:
Your awesome app needs a basic authentication, users management, user profiles, user galleries and a chat.
Each one of these could be a module, and implement its own GraphQL schema and its own logic, and it could depend on other modules to provide some of the logic.
Here’s a simple example for a GraphQL Schema as we described:

But if we think of apps in terms of features and then separate the schema by module, the modules separation will look like so:

This way, each module can declare only the part of the schema that it contributes, and the complete schema is a representation of all merged type definitions. Module can also depend, import and extend and customize the contents on other modules (for example, User module, comes with Auth inside it)
The result of course, will be the same, because we are merging the schema into a single one, but the codebase will be much more organized and each module will have its own logic.
Reusability of backend modules
So now that we understood the power of feature-based implementation, it’s easier to grasp the idea behind code reusability.
If we could implement the schema and the core of Auth and User module as “plug-and-play” — we will be able later to import it in other projects, with very minor changes (using configuration, dependency injection, or module composition).
How could we reuse complete modules that hold part of a schema?
For example, let’s take a User type.
Most of User type schemas will contain id, email and username fields. The Mutation type will have login and the Query will have user field to query for a specific user.
We can re-use this type declaration.
The actual implementation might differ between apps, according to the authentication provider, database and so on, but we can still implement the business logic in a simple resolver, and use dependency injector and ask the app that’s using the module to provide the actual authentication function (of course, with a complete TypeScript interface so we’ll know that we need to provide it ;) ).
Let’s take it one step further. If we would like to add a profile picture to a user, we can add a new module named UserProfile and re-declare the User and Mutation types again:
type User {
profilePicture: String
}
type Mutation {
uploadProfilePicture(image: File!): User
}This way, GraphQL Modules will merge the fields from this User type into the complete User type, and this module will only extend the User type and Mutation type with the required actions.
So let’s say that we have the schema — how can we make this module generic and re-use it?
This is how you declare this module:
import { GraphQLModule } from '@graphql-modules/core';
import gql from 'graphql-tag';
import { UserModule } from '../user';
import { Users } from '../user/users.provider';
export interface IUserProfileModuleConfig {
profilePictureFields ?: string;
uploadProfilePicture: (stream: Readable) => Promise<string>;
}
export const UserProfileModule = new GraphQLModule<IUserProfileModuleConfig>({
imports: [
UserModule,
],
typeDefs: gql`
type User {
profilePicture: String
}
type Mutation {
uploadProfilePicture(image: File!): User
}
`,
resolvers: config => ({
User: {
profilePicture: (user: User, args: never, context: ModuleContext) => {
const fieldName = config.profilePictureField || 'profilePic';
return user[fieldName] || null;
},
},
Mutation: {
uploadProfilePicture: async (root: never, { image }: { image: any }, { injector, currentUser }: ModuleContext) => {
// using https://www.apollographql.com/docs/guides/file-uploads.html
const { stream } = await image;
// Get the external method for uploading files, this is provided by the app as config
const imageUrl = config.uploadProfilePicture(stream);
// Get the field name
const fieldName = config.profilePictureField || 'profilePic';
// Ask the injector for "Users" token, we are assuming that `user` module exposes it for us,
// then, update the user with the uploaded url.
injector.get(Users).updateUser(currentUser, { [fieldName]: imageUrl });
// Return the current user, we can assume that `currentUser` will be in the context because
// of resolvers composition - we will explain it later.
return currentUser;
},
},
}),
});We declare a config object, and the app will provide it for us, so we can later replace it with a different logic for uploading.
Scaling the codebase
Now that we broke our app into individual modules, once our codebase grows, we can scale each module individually.
What do I mean by scaling a codebase?
Let’s say we start to have code parts we want to share between different modules.
The current way of doing it in the existing GraphQL world is through a GraphQL context.
This approach has proven itself to work, but at some point it becomes a big hassle to maintain, because GraphQL context is an object, which any part of the app can modify, edit and extend, and it can become really big pretty quickly.
GraphQL modules let each module extend and inject fields to the `context` object, but this is something that you should use with caution, because I recommend the `context` to contain the actual `context` — which contains data such as global configuration, environment, the current user and so on.
GraphQL modules only adds one field under the context, called injector which is the bridge that lets you access your GraphQLApp and the application Injector, and it lets you fetch your module’s config and providers.
Modules can be a simple directory in a project or in a monorepo, or it could be a published NPM module — you have the power to choose how to manage your codebase according to your needs and preferences.
Dependency Injection
GraphQL Modules’ dependency injection is inspired by .NET and Java’s dependency injection which has proven itself to work pretty well over the years. With that being said, there were some issues with .NET and Java’s APIs, which we’ve tried to list and go through. We ran into some pretty interesting conclusions.
We’ve learn that it’s not something that should be forced. Dependency injection makes sense in some specific use cases and you should need to use it only when it’s necessary and when it helps you move faster. So this concept should come more and more in handy as we scale up, we can simplify things, maintain our code with ease and manage our teams’ contributions!
Having GraphQL Modules deployed across all of our Enterprise customers while also being used on our smaller applications, lead us to believe that we’ve found the optimal point of where you should use the concept of dependency injection, and when not.
We’ve also came with the optimal API for dependency injection. It’s extremely easy to understand, and use.
After a long research of the existing dependency injection solutions for JavaScript, we’ve decided to implement a simple Injector, that supports the needs of GraphQL-Modules ecosystem, and support circular dependencies and more.
We’ve simplified the Dependency Injection API and exposed to you only the important parts, that we believe that are necessary for a GraphQL server development.
Authentication
Check out the related blog post we wrote about it: https://medium.com/the-guild/authentication-and-authorization-in-graphql-and-how-graphql-modules-can-help-fadc1ee5b0c2
Testing and mocking
On our Enterprise applications, when we started using dependency injection, we no longer had to manage instances and bridge them together.
We gained an abstraction that allowed us to test things easier and mock all http requests.
Yes, mocking. DI really shines here.
Thanks to mocking we can simulate many scenarios and check the backend against them.
And when your codebase grows, you need to start thinking about managing dependencies between modules and how to avoid things like circular dependencies — unless you use DI which solves that problem for you.
With the power of dependency injection, you can easily create a loose connection between modules, and base this connection on a token and on a TypeScript interface.
It also means that testing is much easier — you can take your class/function and test it as an independent unit, and mock its dependencies easily.
Summary
We see GraphQL Modules as the framework that finally being built from the ground up on the new and exciting capabilities of GraphQL and Apollo, while combining it in the right way with good old software best practices for scale like modularizations, strong typings and dependency injection.
Now go and try it out — https://graphql-modules.com/
All posts about GraphQL Modules
Why is True Modular Encapsulation So Important in Large-Scale GraphQL Projects?
Why did we implement our own Dependency Injection library for GraphQL-Modules?
Writing a GraphQL TypeScript project w/ GraphQL-Modules and GraphQL-Code-Generator
Authentication and Authorization in GraphQL (and how GraphQL-Modules can help)
Follow us on GitHub and Medium, we are planning to release many more posts in the next couple of weeks about what we’ve learned using GraphQL in recent years.